Problem
When taking native database backups for EC2 everyone prefers to store the backups in Amazon S3 as it is durable and cost effective but the questions you need ask yourself while transferring the backups are the following,
- Are the backups going to S3 over internal backbone network?
- Are you using temporary credentials to authenticate to S3 from your EC2 servers? You are sure that you have no plain text keys stored on the server?
- Is the access to the bucket where the backups are stored restricted?
If the answers to all of the above is no then this solution is for you.
Solution
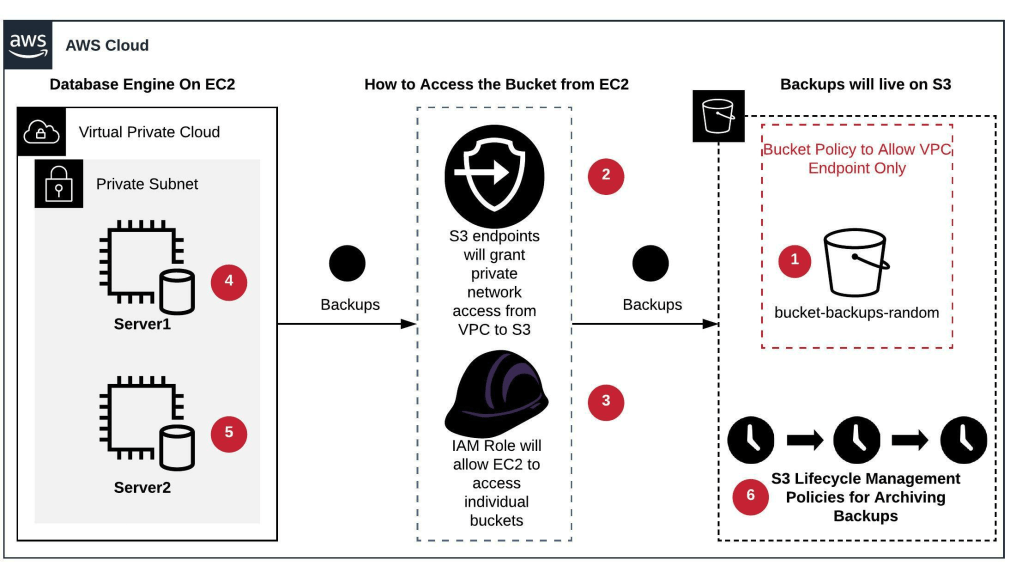
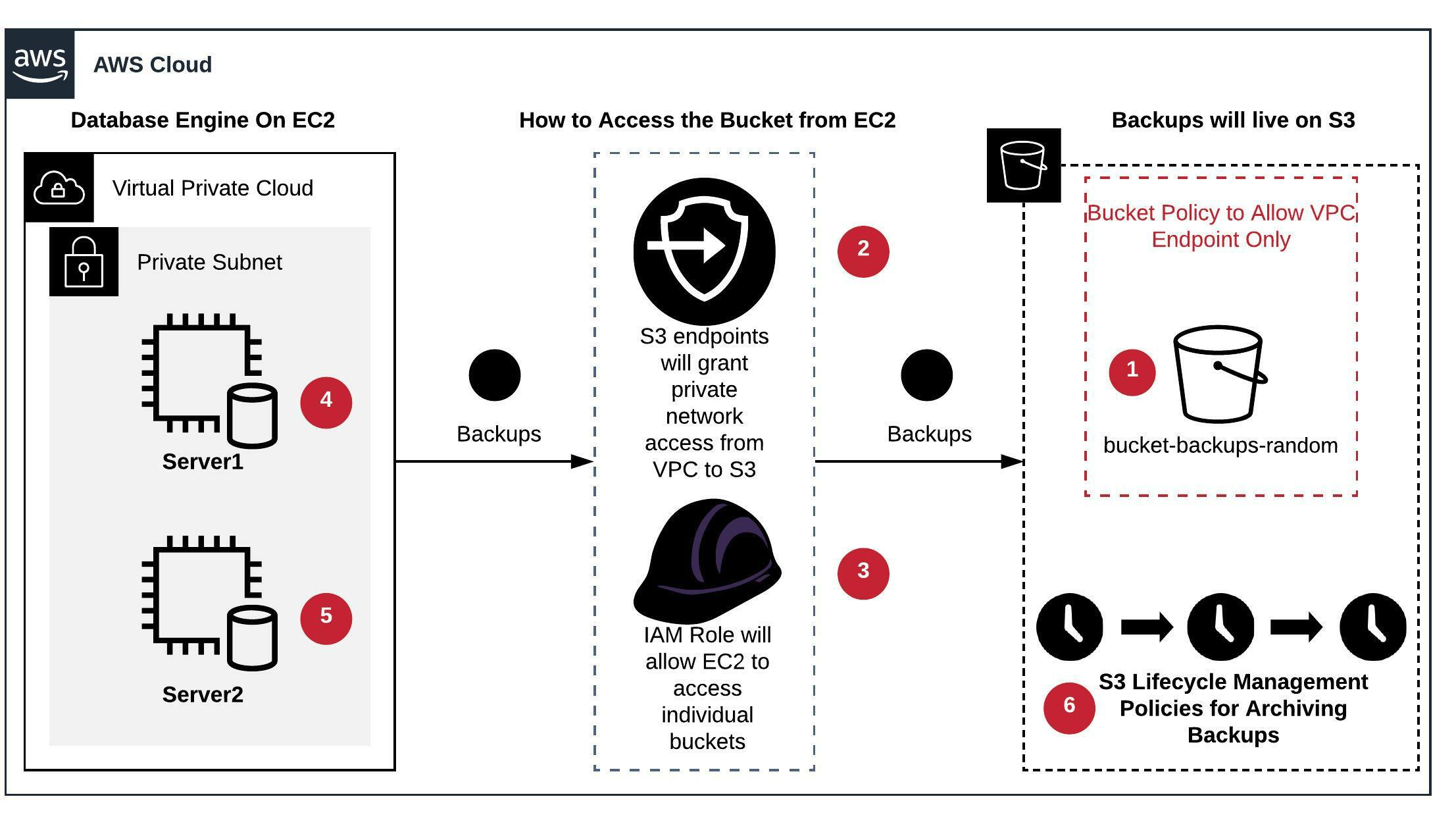
- Setup bucket(s) and prefixes in S3 for storing backups.
- Ensure that the bucket has correct encryption settings enabled
- Configure S3 endpoint from the VPC where your EC2 machines are hosted. This will allow private network access from your EC2 machines to S3 buckets. Ensure to create a bucket policy to allow only VPC endpoint(s) and other allowed actors.
- Create individual IAM roles for individual buckets granting read, write and list privileges to the bucket(s).
- This role needs to be assigned to the concerned EC2 machine with SQL Server on it. Now the EC2 machine can read and write objects to their buckets privately without having to specify any passwords or access\secret keys. We will configure a sync from local EBS volume where the backups are taken to write all backups to S3 whenever new one’s are available or when backups are taken.
- The sync process can easily be automated by using AWS s3 sync command. You will need to ensure that you have AWSCLI installed on the EC2 instance and then you can schedule the AWS s3 sync using cron job or task scheduler.
- Same as step#4 but on the other instance(s) or server(s).
- We can then set up lifecycle rules based on your retention to transfer least accessed backups to S3-IA and then moving them to glacier for archival. They can later be removed as per your defined retention policies. This will all be managed automatically by S3 lifecycle management rules.
